
From My Sensor With Love

Photo by Carbon Visuals
IGLUS is currently running an interesting Smart Cities MOOC on Coursera. In this second installment, Matthias Finger and his team focus on the impact of digitization on urban infrastructures looking specifically at energy and mobility. The course is as well structured as the previous one and IGLUS once again invited guests to elaborate on theoretical aspects from a practitioner’s viewpoint. One of the guests, Prof. Boi Faltings of EPFL, speaks about his research in crowdsourced air quality using commercial origins Laser Egg sensors.
Data Donors with IoT
The use of sensors is pervasive throughout the Smart Cities narrative as they allow the capture of physical metrics and their transformation into machine formats. Internet of Things spans here from data collection using traditional Supervisory Control And Data Acquisition (SCADA) from industrial systems to transport vehicles to home appliances consumer goods and DIY devices.
What is interesting in Professor Faltings’ example is that it also involves the use of crowds. Some of you might recall the #AirQualityEgg which initially used DIY hardware feeding an account on Xively (formerly Pachube). The devices adhered to an ingestion API and Xively exposed the data again via consumption API for anyone interested to visualize or analyze the data. Eventually, the devices would be sold departing from the original DIY spirit. The newer devices now use OpenSensors.io to store their data, but the principle is roughly the same.
The Digitization Layer
The IGLUS way to frame the transition to smart cities is centered around a data layer sandwiched between existing urban infrastructure sub-systems such as energy and mobility and the urban services exposed to citizens.
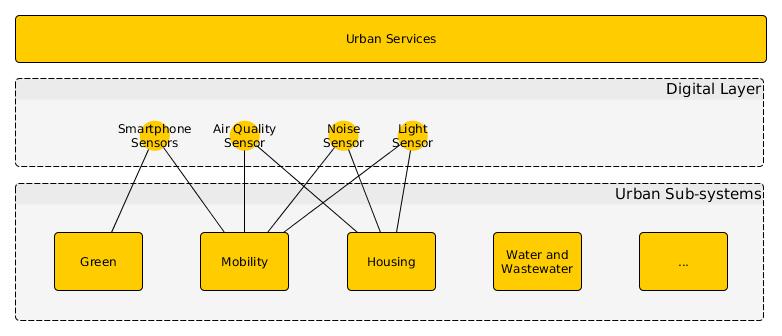
Another example of urban infrastructure is water and wastewater systems from households and industrial facilities. The new digitization layer can be thought of having 3 planes: a physical plane where things gain wired or wireless access, the network plane (e.g. TCP/IP) and a third plane of addressable endpoints for things and applications. I tweaked it slightly to depict sensors as endpoints e.g. how smartphone cameras can be used to sense trees or noise sensors collect data alongside roads.
Given these planes, adoption of standards play a decisive role in the interoperability of devices. Think of the way smart street lights use wireless sensor networks to transmit data from one pole to another until an aggregation relay is reached which can transmit data to a cloud server perhaps using a wired connection? The data collected by commercial devices also raises important questions of idenfiability and accessibility. Let’s stick to air quality as example of crowdsourcing and IoT as it has been covered on this blog before. Three groups can be identified showing interest and initiative in the use of IoT and crowdsourcing.
- Public Sector
- Some cities have the opportunity to deploy mid-range sensors placing them on public buildings or lamp posts. One such initiative is Chicago’s Array of Things which exposes noise or temperature data to its citizens. Another example is Amsterdam’s Smart Citizen Lab which sensitizes its citizens to the role of data through workshops and a DIY kit used in other places.
- Civil Society
- Scientists, activists, makers and citizens come together to discuss and co-create a solution as in the #AirQualityEgg example mentioned above. Journalists are also turning to sensor data for their stories e.g. see presentation by @digitalamysw or post by @javaun. Finally, we also find here university efforts such as UCL’s Mapping for Change.
- Private Sector
- Vendors are proposing specialized products with sensors directly to consumers. Think of including our beloved smart phone in the list of devices. Mobile operators have access to network data as we cross the urban space from cell to cell or through the apps to which we grant access to the many sensors the phones have. See for example how Swisscom helps my town with urban planning questions by exploiting cellular network events left behind by commuters. This example is interesting because the device is part of a larger service offering.
Challenges
The IGLUS team identified challenges around the digitization layer which I will revisit here and extend as I am interested in the crowdsourcing perspective. Crowdsourcing would imply that the devices are partially or totally owned by individuals. The ITU Telecommunications Standardization Sector (ITU-T) recognizes the importance of standards and seems to be in the process of defining requirements, platforms and functional architectures supporting crowdsourcing and IoT.
- Standards
- Let’s first re-consider the 3 planes mentioned above and some of the emerging standards. I’ll use here specifically OSI layer types. These include Ethernet, WiFi, Bluetooth, ZigBee as well as cellular, NB-IoT or LoRaWAN for the physical and link layers, IP or 6LowPAN with TCP or UDP for the network layer, and HTTP or CoAP for the end-to-end layer just below the application. But will the ITU-T study group also look at the other challenges?
- Data Ownership
- The original #AirQualityEgg pushed data into a pre-configured Xively account through an API. Provisioning was based on dynamic generation of a feed identifier and key from the the sensor’s MAC address and a SHA1 hash. Reading from a personal account would be no problem. Deletions would not be possible but advanced users could work around limitations. In the case of the Swisscom mobile traces mentioned above, the data also remains with Swisscom and cannot even be accessed by others. Questions of ownership remain tricky in light of technical constraints to provide quick access to aggregated data. Which brings me to the next aspect.
- Location
- While it may be convenient to think of data centers or even cloud providers for data storage, the location will impose new constraints. These can be redundancy problems, interoperability or integration challenges across data centers or incompatible terms and conditions for example. I have mentioned before here that there are decentralized approaches emerging which could also be considered to leave data close to the edge.
- Accessibility
- I am referring to the ability to (1) transmit data to a platform, (2) retrieve data from a platform and (3) perform discovery of other data sources. An example of the first two is ThingSpeak. APIs play here a central role and their standardization and stability are essential. Younger companies are subject to pivots and end up sometimes changing or even retiring APIs which presents a risk. There are alternatives out there, e.g. OGC Sensor Observation Service and 52°North’s client. Sensor data can be stored in all sorts of places. On this blog, under the data tab, I use Google Fusion tables. There are also ongoing efforts to facilitate the discovery of the data sets as shown by this Google Research Blog post.
- Security and Privacy
- Can my sensor be hacked and enslaved into a large distributed DoS attack? Last year’s Dyn cyberattack certainly helped raise some awareness around the risks as we connect more and more connected devices in our homes. This document by the Industrial Internet Consortium provides some guidance on one aspect, namely the protection of API endpoints. Privacy challenges will be related to questions of protocol encryption when data is transmitted or data obfuscation in a way that prevents re-identification from data aggregation with other data sets. See the IERC position paper which touches on how crowdsourcing pushes the envelope of existing ethical and legal concepts.
- Pricing
- The digitization layer includes platforms which expose multiple APIs including ingestion and consumption of data and are also further segregated across user categories. Multi-sided platforms come to mind when considering pricing strategies. For example eBay has buyers on the loss-leader side and sellers on the profit-making side. Operating systems have developers of apps on the loss-leader side and users on the profile-making side. The main principles followed include charging a higher price to the group with less price sensitivity or charge more to the side which benefits most assuming no transaction between them exists. If transactions are possible, charge more to the side which has the best leverage.
- Data Reliability
- Is the sensor data legit? Following a centralized mindset to IoT solutions, machine learning techniques can be applied to detecting outliers in sensor swarms. This idea is mentioned in Prof. Faltings’ interview who explored incentive compatible schemes for community sensing in OpenSense2. Another aspect of reliability of data coming from low-fidelity / high-frequency devices would be that of hardware characteristics. Ontologies could be considered to describe the owner, the devices, etc. The model below (likely inaccurate!) is inspired by an earlier dot.rural Digital Economy Hub publication.
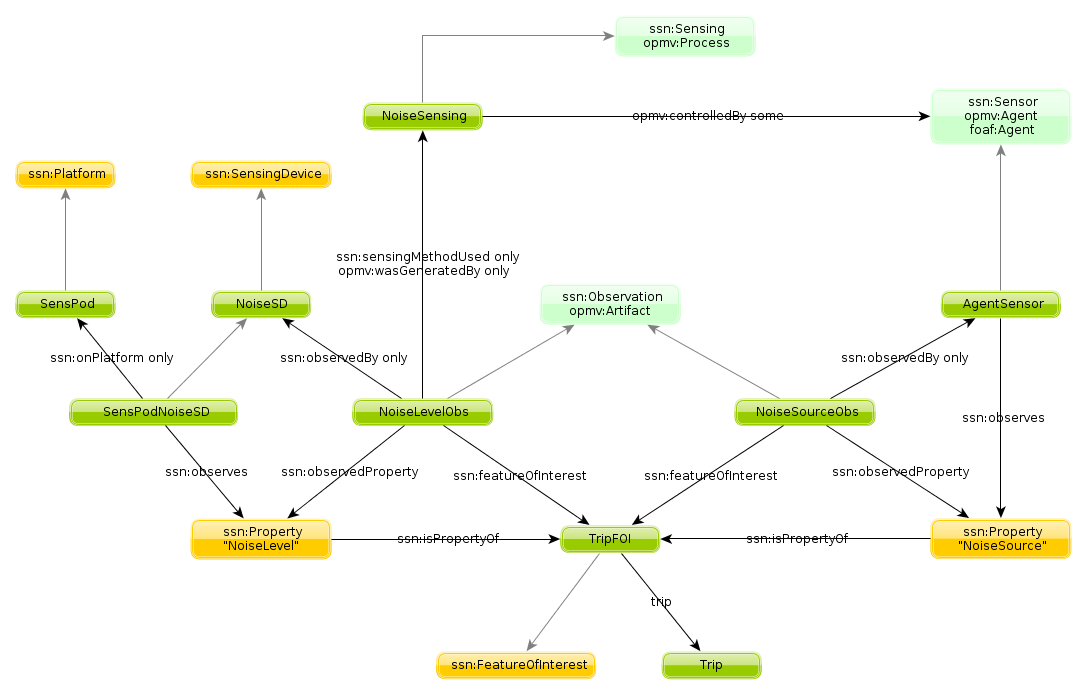
I have since been keeping an eye on Google’s initiatives to markup datasets which is still ongoing. This could be used on the small data I collect using the good old Senspod.
- Participation
- I am adding this challenge to the IGLUS list as it pertains to the crowdsourcing of data which starts with… people! As mentioned in previous posts, citizen science remains to me a great source of inspiration for crowdsourcing data. I like to think cities are made smart with education of its citizens who engage (for intrinsic or extrinsic reasons) in activities to understand and harvest data on a variety of phenomena. UCL ExCiteS has perhaps some wise insights here as they look at ways to scale citizen science to very large number of non-expert participants which they refer to as extreme citizen science
Extreme citizen science is publicly initiated scientific research where individuals engage in the creation and mediation of knowledge to address issues that are of concern to them to bring about change.
UCL ExCiteS sees a continuum from citizen “as sensor” through distributed intelligence then participatory science ultimately to extreme citizen science that may be compelling for cities as they face questions under constrained resources.
Internet of whose Thing?
The digitization of the city spans across sub-systems including energy networks, roads, water and wastewater pipes, or public parks to name a few. Some of these are managed for us citizens by professionals. If you rent, you rely on services to help you with wear & tear. The operator may decide to instrument their building with IoT technology. In other cases, the underlying physical system is collectively owned e.g. parks, outside air where the economic principle of exclusion is more difficult to apply. Once this distinction made, we have all sorts of promising combinations of citizens and organizations prepared to deploy DIY or commercial appliances to extract live data.
Cities are growing and our environment is changing faster and faster. As resilience considerations enter the city’s agenda, so will an increased understanding for complex systems, the need for context-specific understanding and from there the ability to govern change. Standards and regulations are thus unavoidable to empower citizens beyond mere consumers in understanding their environment and acquiring along the way shared models of understanding. It is also up to cities to pull their weight in relation to these challenges and not let Alphabet’s Sidewalk Inc. or IBM decide the path towards digitization and ultimately resilience. There’s way more to IoT and crowdsourcing than being a selfish or a passive data donor. The fabric of the data commons is at stake.
 This material is licensed under CC BY 4.0
This material is licensed under CC BY 4.0